Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers
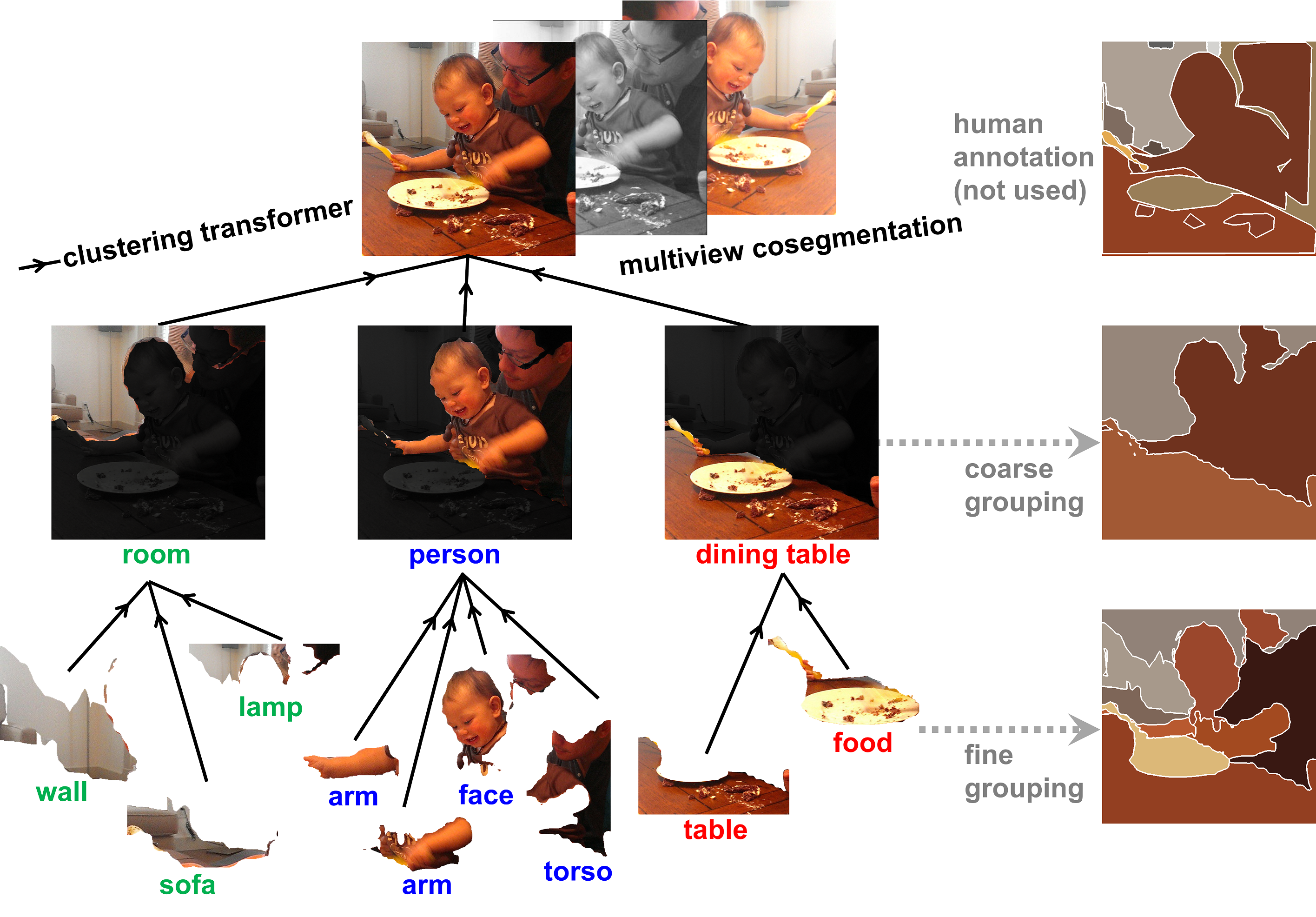
Abstract
Unsupervised semantic segmentation aims to discover groupings within and across images that capture object- and view-invariance of a category without external supervision. Grouping naturally has levels of granularity, creating ambiguity in unsupervised segmentation. Existing methods avoid this ambiguity and treat it as a factor outside modeling, whereas we embrace it and desire hierarchical grouping consistency for unsupervised segmentation.
We approach unsupervised segmentation as a pixel-wise feature learning problem. Our idea is that a good representation must be able to reveal not just a particular level of grouping, but any level of grouping in a consistent and predictable manner across different levels of granularity. We enforce spatial consistency of grouping and bootstrap feature learning with co-segmentation among multiple views of the same image, and enforce semantic consistency across the grouping hierarchy with clustering transformers.
We deliver the first data-driven unsupervised hierarchical semantic segmentation method called Hierarchical Segment Grouping (HSG). Capturing visual similarity and statistical co-occurrences, HSG also outperforms existing unsupervised segmentation methods by a large margin on five major object- and scene-centric benchmarks.
Materials



Code and Models


Citation
@inproceedings{ke2022hsg,
title={Unsupervised Hierarchical Semantic Segmentation with Multiview Cosegmentation and Clustering Transformers},
author={Ke, Tsung-Wei and Hwang, Jyh-Jing and Guo, Yunhui and Wang, Xudong and Yu, Stella X.},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={},
year={2022}
}
Method Highlight
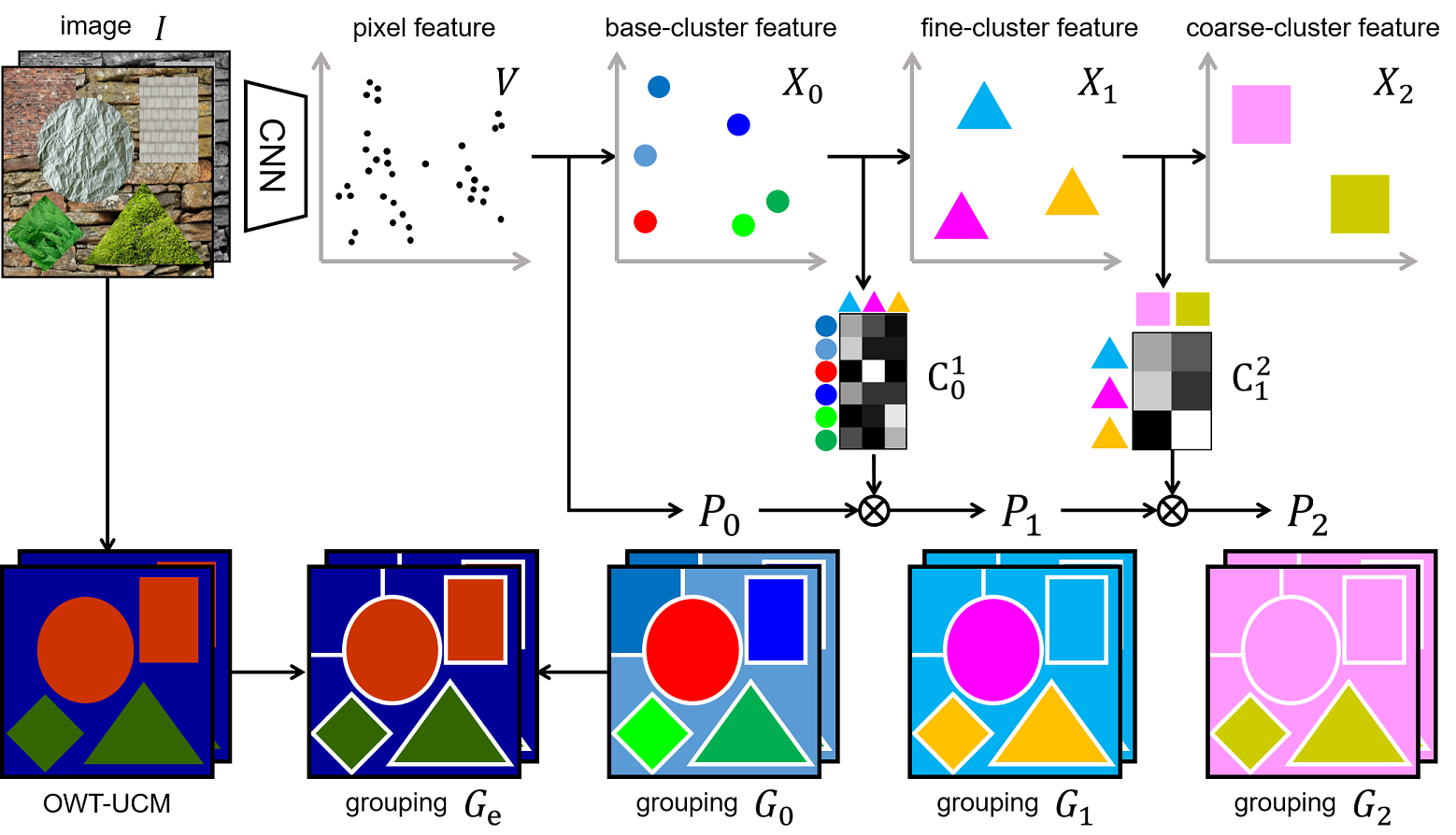
Overview. We aim to learn a CNN that maps each pixel to a point in the feature space V such that successively derived cluster features X0, X1, X2 produce good and consistent hierarchical pixel groupings Ge, G1, G2. Their consistency is enforced through clustering transformers Cll+1 , which dictates how feature clusters at level l map to feature clusters at level l+1. Note that G0 results from clusters of V , and Ge from OWT-UCM edges. Pl is the probabilistic version of Gl, and Gl the winner-take-all binary version of Pl; P0 ∼ G0. For l ≥ 0, Pl+1 results from propagating Pl by Cll+1 . Groupings Ge, G1, G2 in turn impose desired feature similarity and drive feature learning. We co-segment multiple views of the same image to capture spatial consistency, visual similarity, statistical co-occurences, and semantic hierarchies.
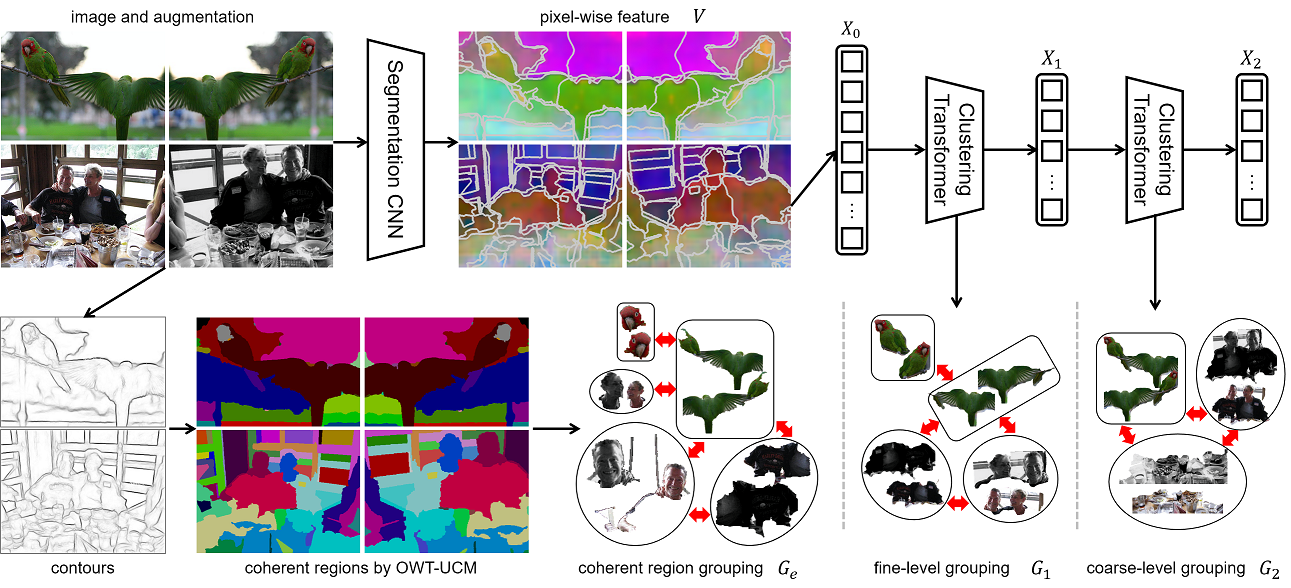
Our model consists of two essential components: 1) multiview cosegmentation and 2) hierarchical grouping . We first produces pixel-wise feature V, from which we cluster to get base cluster feature X0 and grouping G0. Each G0 region is split w.r.t coherent regions derived by OWT-UCM procedure, which is marked by the white lines. We create three groupings--Ge, G1 and G2 in multiview cosegmentation fashion. We obtain Ge by inferring the coherent region segmentation according to how each view is spatially transformed from the original image. Starting with input X0 of an image and its augmented views, we conduct feature clustering to merge G0 into G1, and then, G1 into G2. Based on Ge, G1 and G2, we formulate a pixel-to-segment contrastive loss for each grouping. Our HSG learns to generate discriminative representations and consistent hierarchical segmentations for the input images.
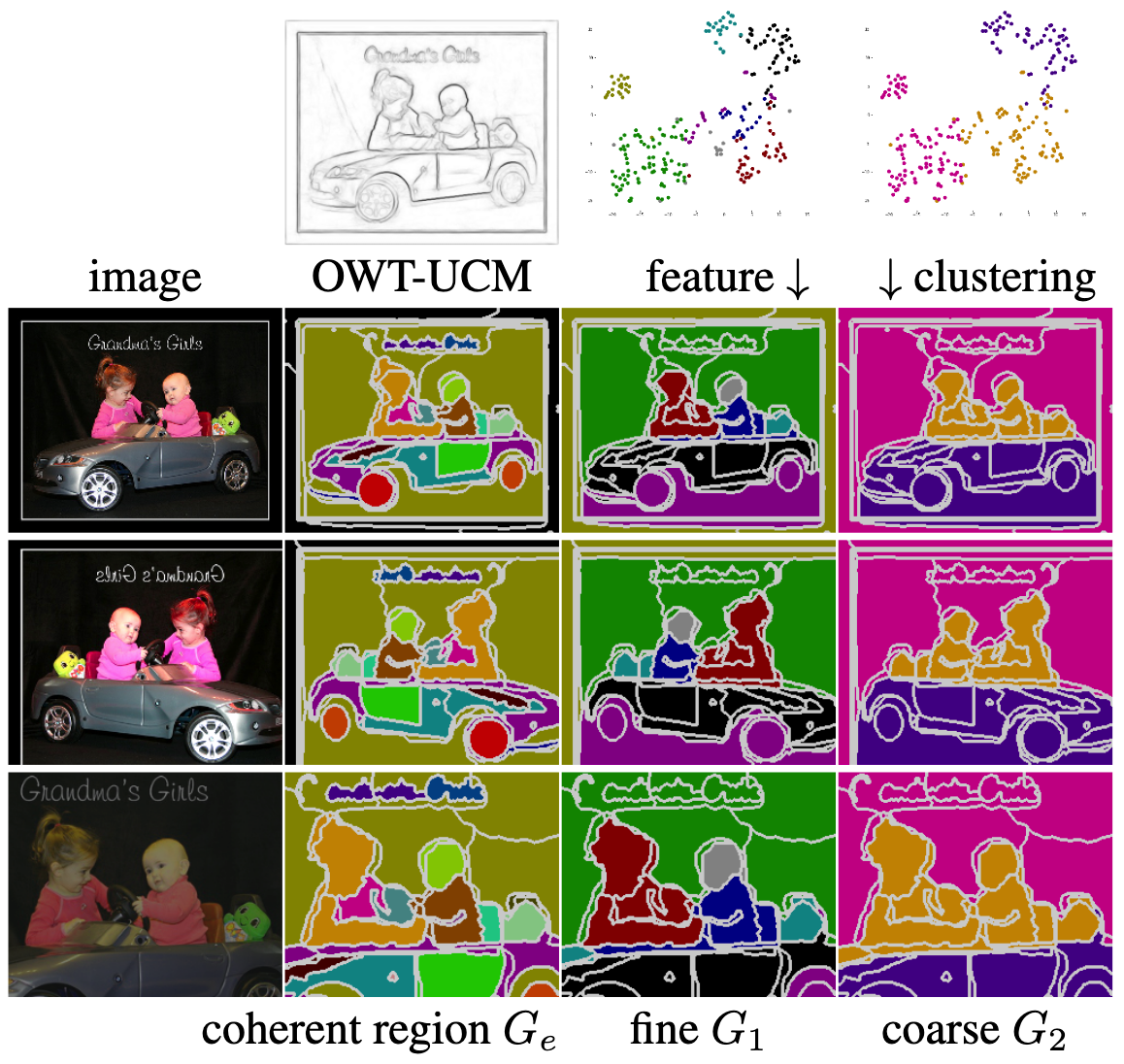
Two kinds of groupings: We co-segment multiple views (Column 1) of the same by OWT-UCM edges (Ge, Column 2) or by feature cluster at fine and coarse levels (G1, G2, Columns 3-4). White lines mark the segments derived from pixel feature clustering and OWT-UCM edges. The color of feature points (pixels) mark grouping in the feature space (segmentation in the image) consistently across rows in the same column, per spatial transformations between views. G2’s coarse segmentations simply merge G1’s fine segmentations, their consistency enforced by our clustering transformers. We formulate a pixel-to-segment contrastive loss (Lf) to optimize pixel-wise features w.r.t certain segmentations. Minimizing Lf(Ge), Lf(G1), Lf(G2) ensures respectively that our learned feature is grounded in low-level coherence, yet with view invariance, and capable of capturing semantics at multiple levels and producing hierarchical segmentations.
Semantic Segmentation over Object- and Scene-centric Datasets.

Our framework generalizes better on different types of datasets. From top to bottom every three rows are visual results from VOC, Cityscapes and KITTI-STEP dataset. The results are predicted via segment retrievals. Our pixel-wise features encode more precise semantic information than baselines.
Hierarchical Image Segmentation.

Our hierarchical clustering transformers capture semantics at different levels of granularity. Top row: our hierarchical segmentation; Bottom row: SE-OWT-UCM. Each image is segmented into 12, 6, 3 regions. Our method reveals low-to-high level of semantics more consistently.
Acknowledgements
This work was supported, in part, by Berkeley Deep Drive, Berkeley AI Research Commons with Facebook, NSF 2131111, and a Bosch research gift.