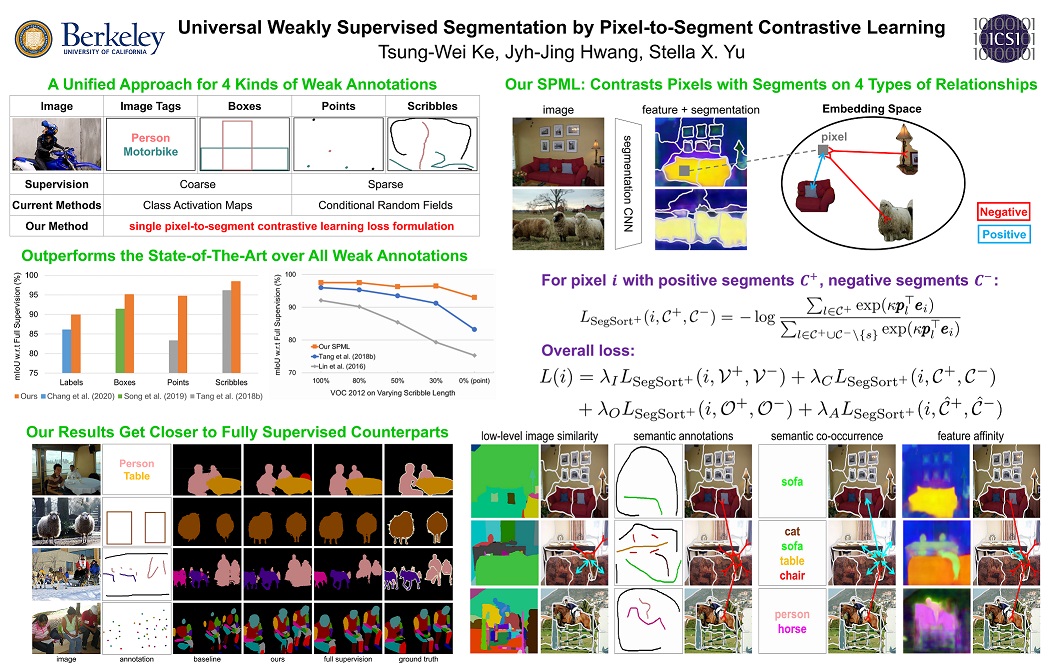
Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning
Abstract
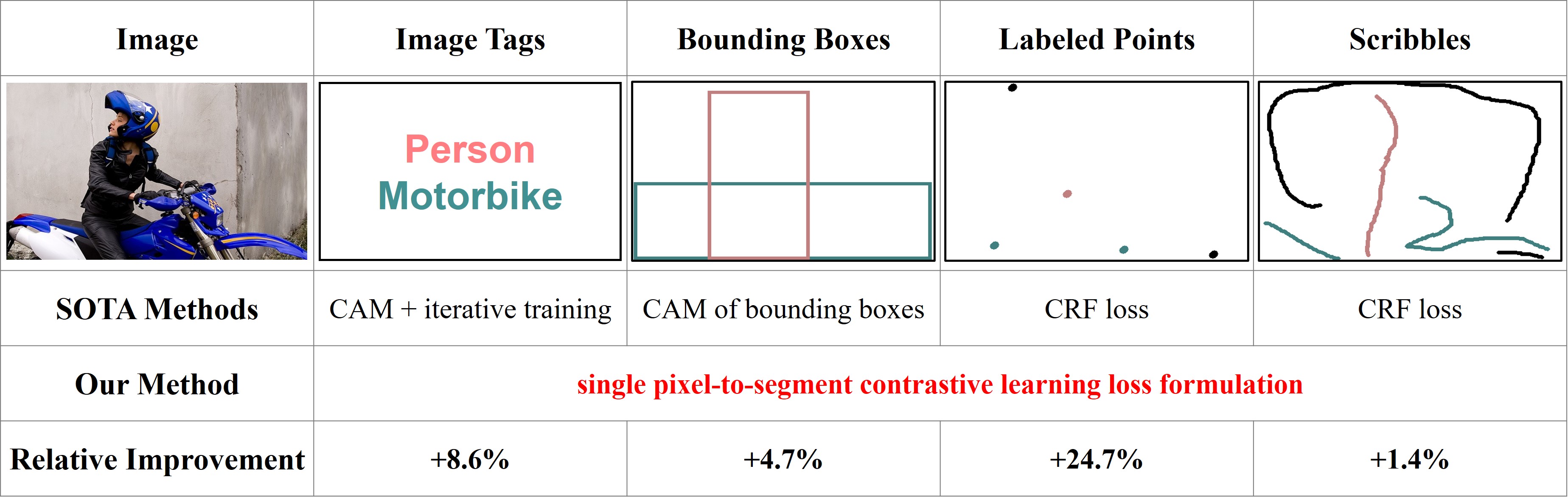
Weakly supervised segmentation requires assigning a label to every pixel based on training instances with partial annotations such as image-level tags, object bounding boxes, labeled points and scribbles. This task is challenging, as coarse annotations (tags, boxes) lack precise pixel localization whereas sparse annotations (points, scribbles) lack broad region coverage. Existing methods tackle these two types of weak supervision differently: Class activation maps are used to localize coarse labels and iteratively refine the segmentation model, whereas conditional random fields are used to propagate sparse labels to the entire image.
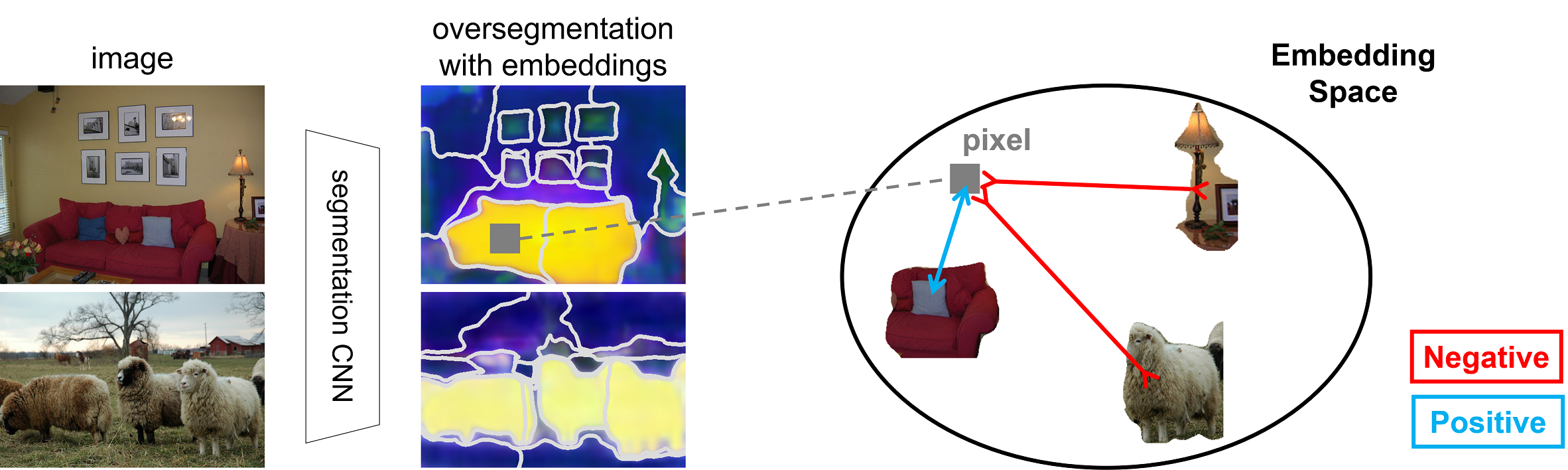
We formulate weakly supervised segmentation as a semi-supervised metric learning problem, where pixels of the same (different) semantics need to be mapped to the same (distinctive) features. We propose 4 types of contrastive relationships between pixels and segments in the feature space, capturing low-level image similarity, semantic annotation, co-occurrence, and feature affinity They act as priors; the pixel-wise feature can be learned from training images with any partial annotations in a data-driven fashion. In particular, unlabeled pixels in training images participate not only in data-driven grouping within each image, but also in discriminative feature learning within and across images. We deliver a universal weakly supervised segmenter with significant gains on Pascal VOC and DensePose.
Materials


Code and Models


Citation
@inproceedings{ke2021spml,
title={Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning},
author={Ke, Tsung-Wei and Hwang, Jyh-Jing and Yu, Stella X},
booktitle={International Conference on Learning Representations},
pages={},
year={2021}
}
Method Highlight
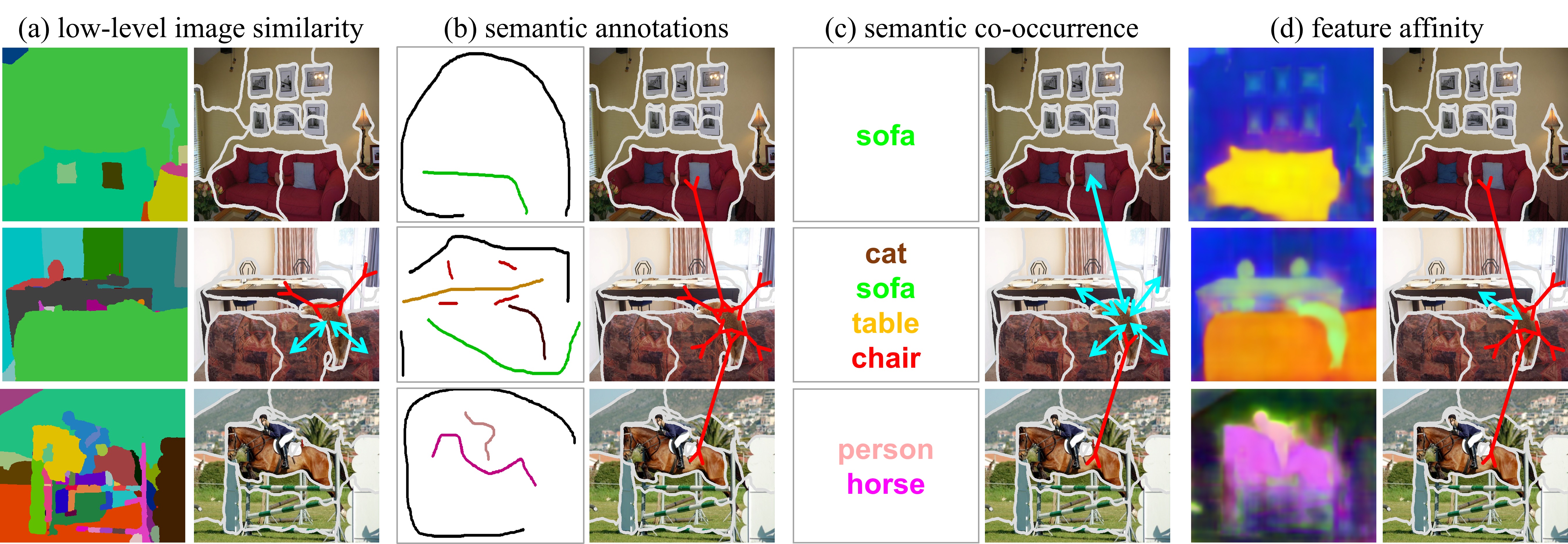
Four types of pixel-to-segment attraction and repulsion relationships. A pixel is attracted to (repelled by) segments: a) of similar (different) visual appearances such as color or texture, b) of the same (different) class labels, c) in images with common (distinctive) labels, d) of nearby(far-away) feature embeddings. They form different positive and negative sets.
Semantic Segmentation w.r.t Different Types of Annotations

Context-Aware Segment Retrieval via Learned Pixel-wise Feature

Acknowledgements
This work was supported, in part, by Berkeley Deep Drive and Berkeley AIResearch Commons with Facebook. This work used the Extreme Science and Engineering Dis-covery Environment (XSEDE), which is supported by National Science Foundation grant numberACI-1548562. Specifically, it used the Bridges system, which is supported by NSF award numberACI-1445606, at the Pittsburgh Supercomputing Center (PSC).